Lemma
AI Research Commercialization Platform — From Paper to Fundable Spinout
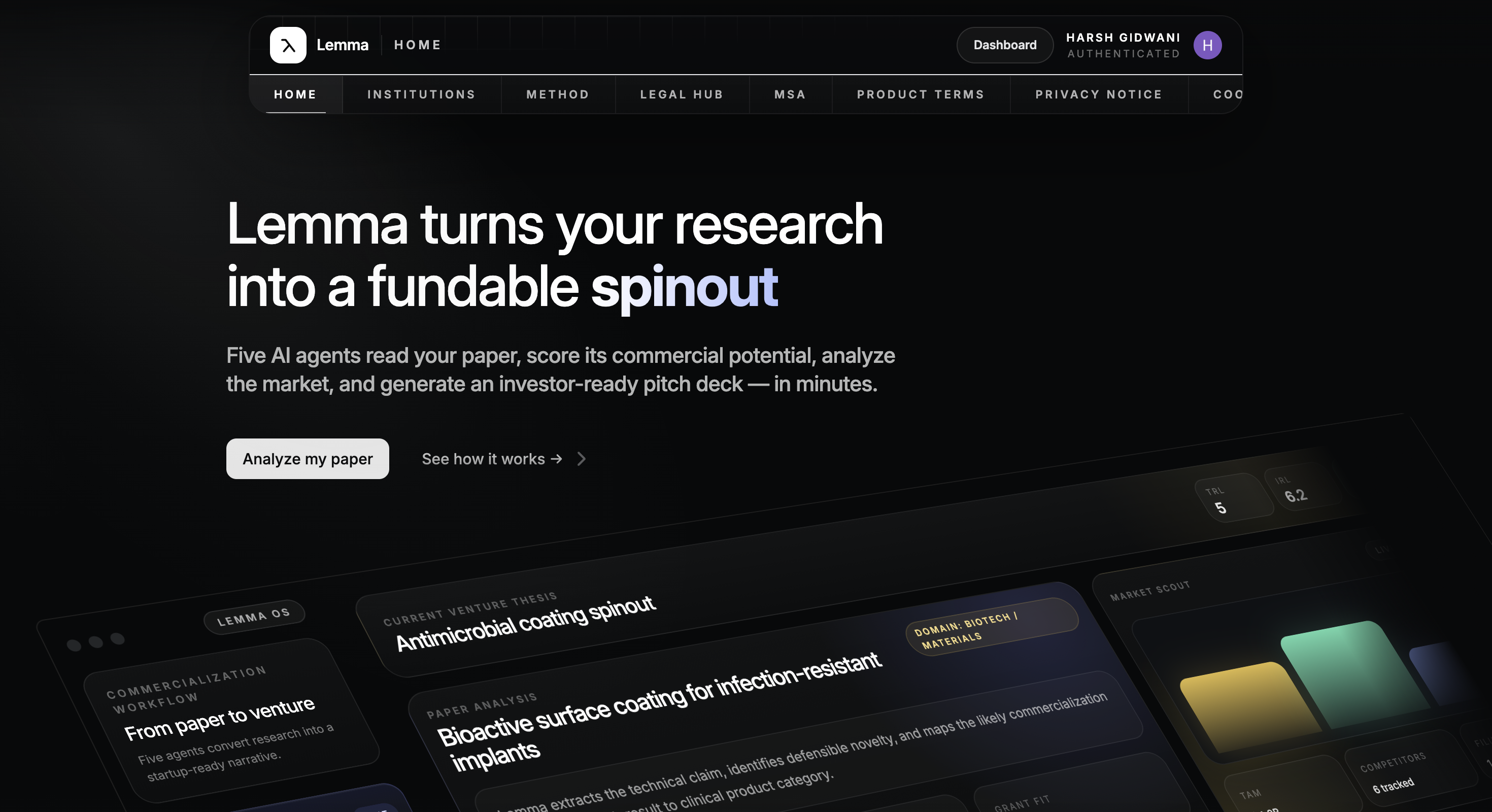
Lemma turns research into a fundable spinout. Upload a research paper and five specialized AI agents take over — understanding the paper and its core claim, scoring technology & investment readiness (TRL/IRL), mapping market demand, competitors and patent signals, estimating feasibility across team, timeline, capital and grant fit, and framing the venture narrative into an investor-ready pitch deck — all in minutes.
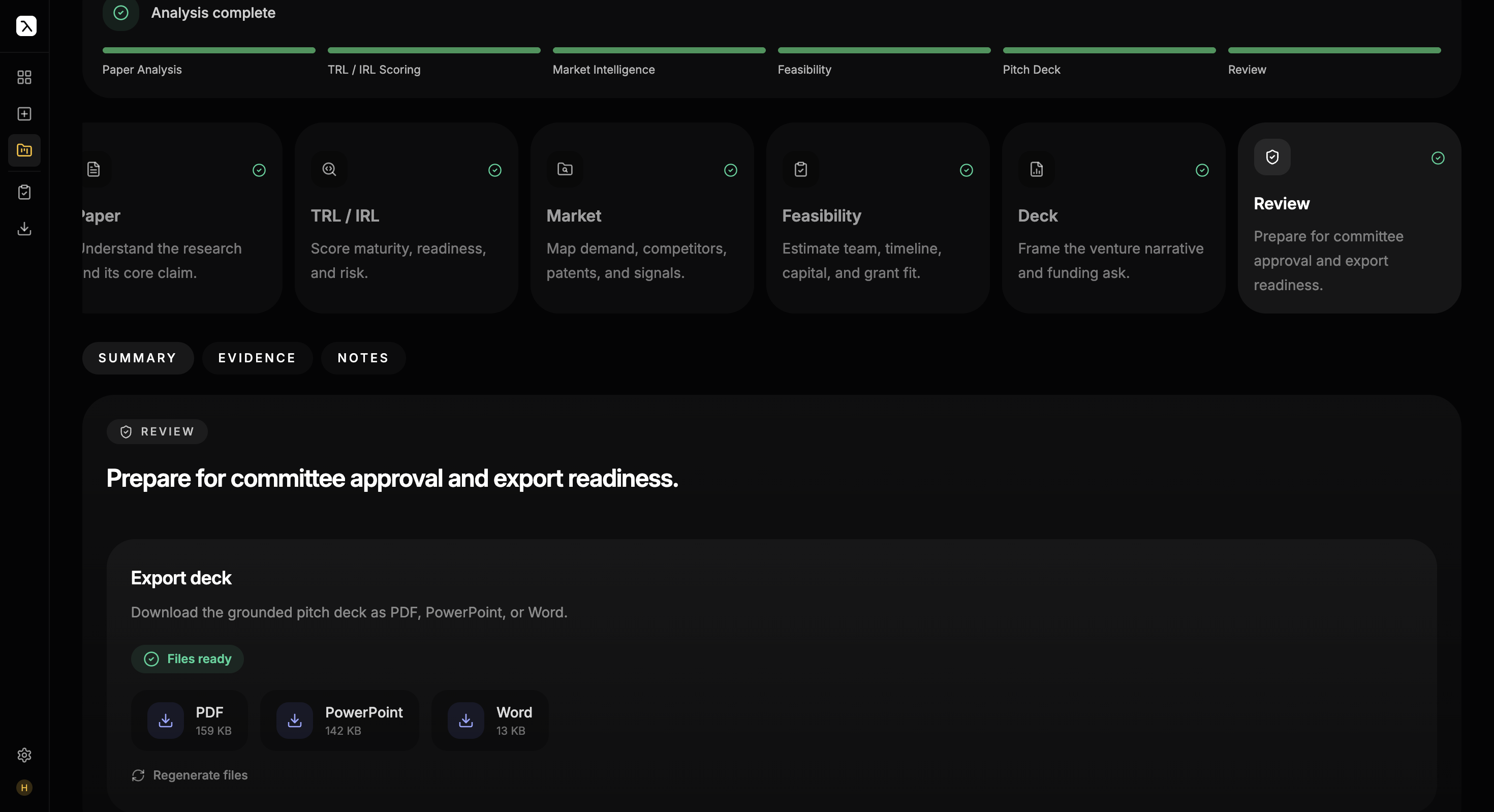
The platform features a six-stage analysis workflow with grounded evidence and hallucination checks, collaborative annotation with citations and TRL evidence highlighting, research gap analysis, and one-click export of the generated pitch deck to PDF, PowerPoint, or Word. Built for research you haven't published yet: end-to-end encryption, zero data retention, and institutional-grade privacy designed to meet the trust requirements of TTOs and incubation cells.
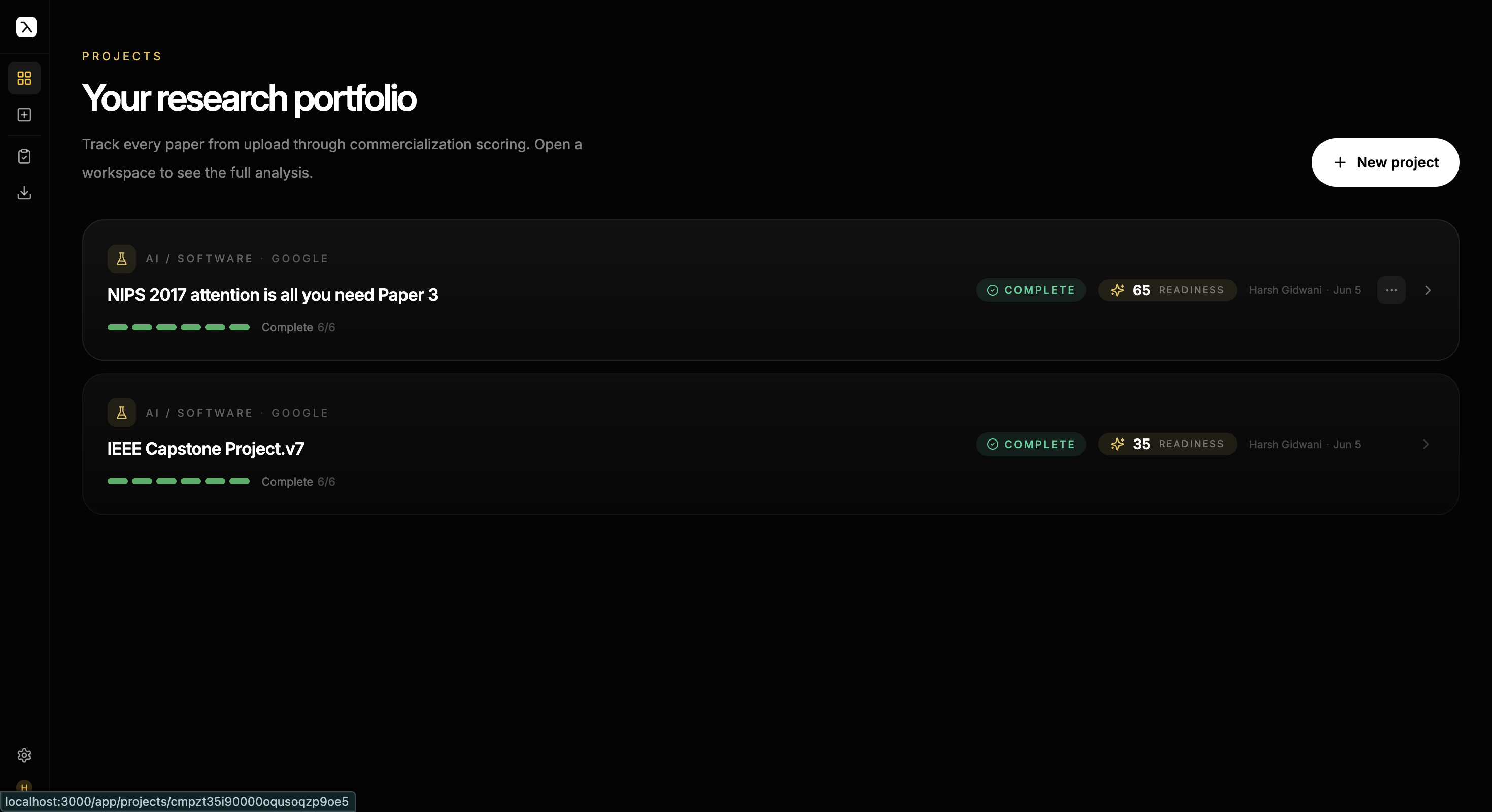
TTOs sit on backlogs of papers and need first-pass commercialization verdicts. Manual review takes experts days per paper; single-prompt LLM evaluation invents market figures and readiness scores nothing can be traced to.
Three runtime planes: fast Next.js 14 API routes, a durable Inngest
pipeline running five agents in isolated step.run() blocks with 3× retries, and a
Pusher + polling notification layer. Neon Postgres via Prisma persists one schema-validated model
per agent output.
Hallucinated market data; multi-minute LLM jobs on serverless timeout limits; partial failures mid-pipeline (search down, model 503s); keeping five agents' outputs mutually consistent; unreliable LLM output shapes.
Closed-world retrieval (market synthesis can only cite URLs actually
retrieved via Tavily), a ref-menu restricting the pitch builder to enumerated upstream facts,
adversarial critique agents at three points with bounded one-shot regeneration, skip-don't-fail
semantics for non-core stages, and dual Zod + Gemini responseSchema enforcement.
Live in production at uselemma.vercel.app — paper to fully-cited investor deck in minutes, with every slide claim traceable to a source URL or upstream finding, consistent across PDF, PPTX, and DOCX exports. Full architecture write-up in the dedicated case study.
💼 For detailed project information, technical documentation, or collaboration opportunities, please contact me at harshgidwani2007@gmail.com