Product
What it looks like
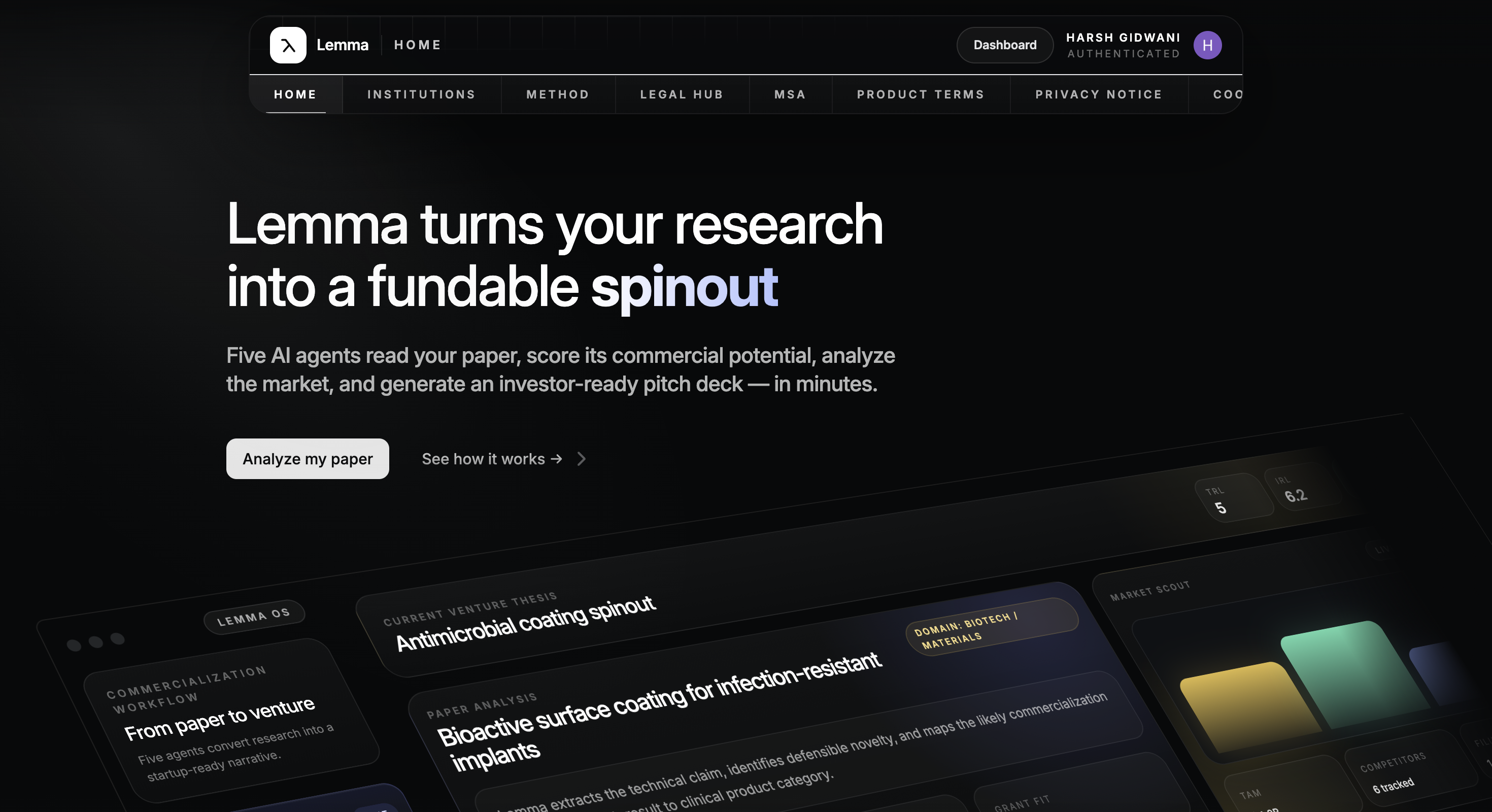
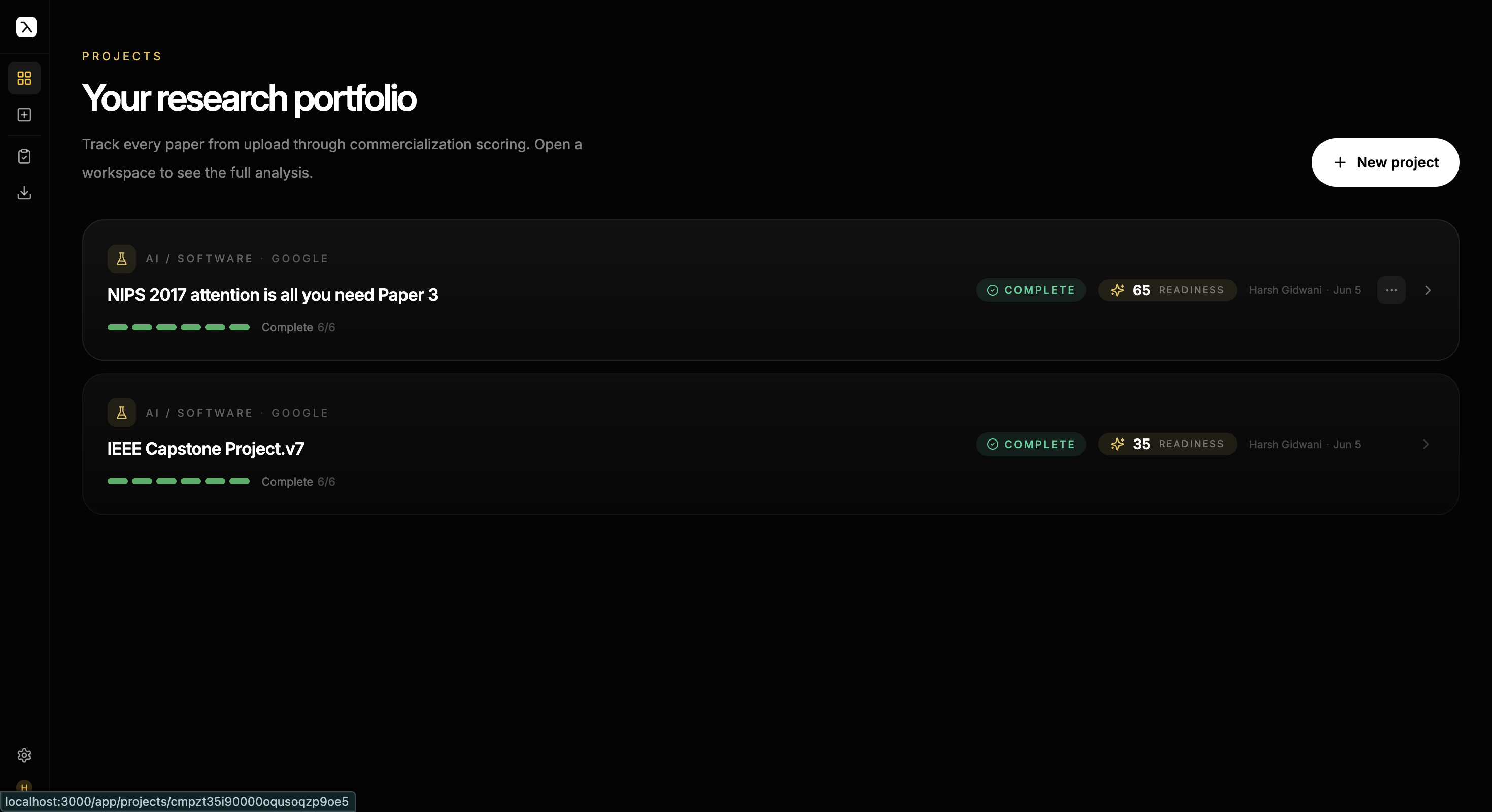
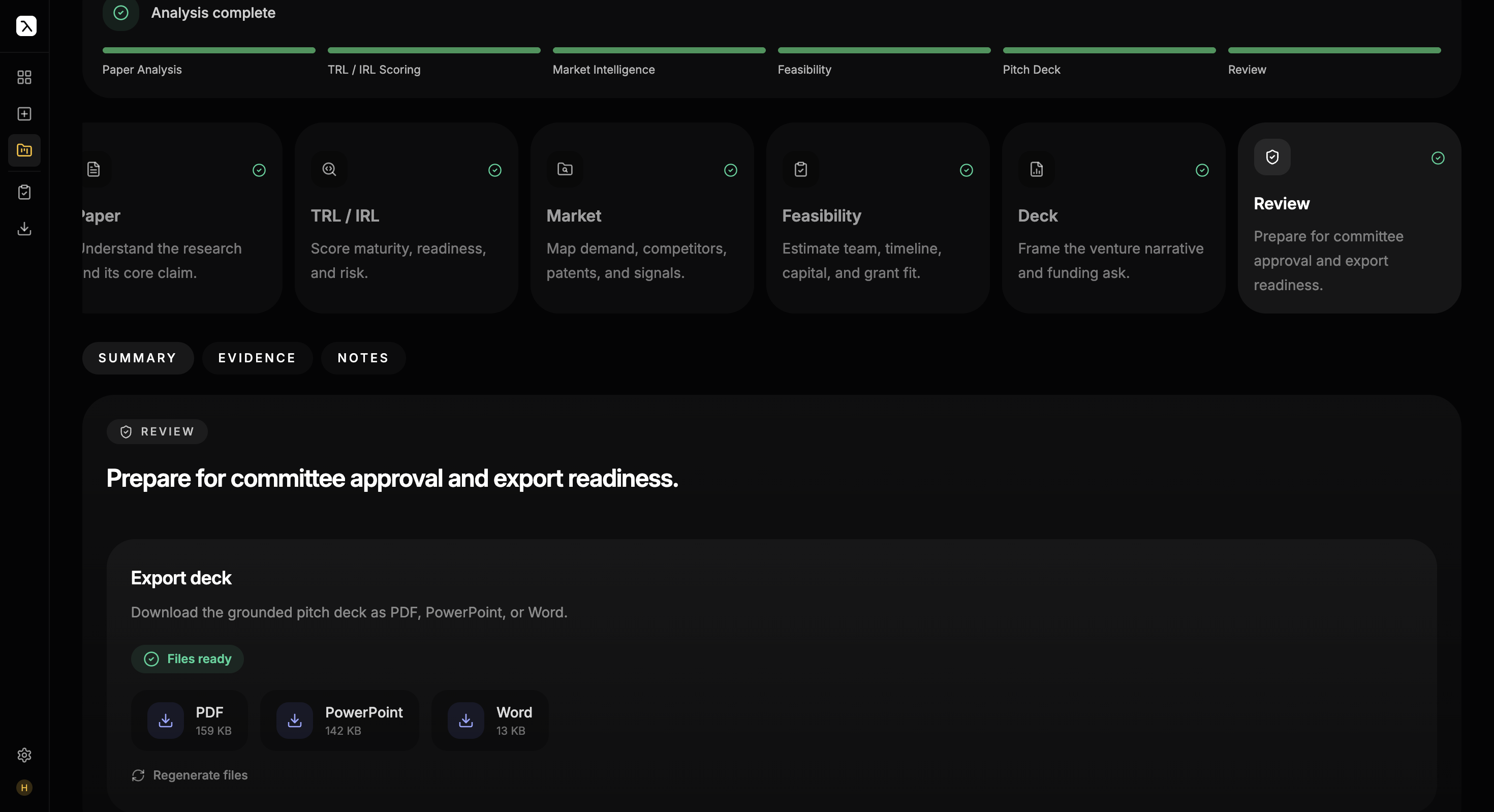
A commercialization evaluation platform for Technology Transfer Offices. Upload a research paper and five grounded AI agents score its commercial potential, then compose a fully-cited investor deck — on durable serverless workflows that survive failures mid-run.
Technology Transfer Offices sit on backlogs of research papers and need to decide which are worth commercializing. Doing this manually takes domain experts days per paper. Doing it with a single LLM prompt is fast but untrustworthy: market sizes get invented, readiness levels are guessed, and nothing in the output can be traced back to a source. Lemma's design goal was an automated first-pass evaluation in which every factual claim is traceable end-to-end — from a slide bullet in the exported deck back to a retrieved URL or an upstream agent finding.
API routes stay deliberately fast; all LLM work happens in a durable background pipeline; progress reaches the browser through real-time events with polling as a fallback. Each plane can fail independently without taking down the others.
Each agent's output is validated against a Zod schema before persistence — and the same schema is converted to
a Gemini responseSchema, so the
model is constrained at generation time and checked at parse time. Amber markers are adversarial
critique passes.
The analyze endpoint only flips status to PROCESSING and fires the event — no LLM work on the request path, so the API responds in milliseconds.
Extracts abstract, novelty, domain, and key claims with confidence levels. Rejects non-research documents (financial reports, textbooks) outright.
An adversarial agent audits the analysis against the source PDF.
Scores Technology and Investment Readiness Levels, suggests a commercialization pathway (spin-off / licensing / partnership), and flags risks.
Stage 1 is retrieval-only: Tavily searches for competitors, funding signals, patents, and market sizing; results are persisted verbatim. Stage 2 lets Gemini see only the retrieved sources — a validator rejects any figure whose sourceUrl isn't in the retrieved set, feeding errors back into a bounded retry loop (max 3 attempts).
Pure reasoning, no retrieval. Timeline and capital estimates are explicit ranges with required confidence and reasoning fields — the schema rejects max ≤ min as a false-precision guard.
Audits reasoning traceability and over-confident estimates; one regeneration allowed on CRITICAL findings.
Composes investor-deck slides. A ref menu enumerates every citable
upstream fact (e.g. market.tam,
paper.keyClaims[2]) as the
model's only citation vocabulary — it structurally cannot invent facts.
TTO staff evaluate results before export. All three exporters consume the same normalized RenderDeck model, so the formats cannot disagree on content or grounding — and every export renders visible per-slide Sources citations.
Every problem below is a general production-LLM problem — context limits, hallucination, orchestration, long-running tasks — solved with specific, verifiable mechanisms in the Lemma codebase.
Re-feeding the entire PDF to all five agents would blow up token costs, latency, and attention quality — later agents would drown in raw text.
Only Agent 1 reads the PDF. Every downstream agent consumes compact, schema-validated structured
outputs (PaperData, TrlIrlData…) — prompt chaining with typed contracts
instead of raw-text relay. The TRL scorer is deliberately forbidden from re-reading the PDF.
Market sizing is exactly where investors check numbers — an invented TAM kills credibility, and a single-prompt approach invents them constantly.
Retrieval and synthesis are split into separate stages. The synthesis model sees only
persisted Tavily results; a validator rejects any figure citing a URL outside the retrieved set and
feeds the Zod errors back into a bounded retry prompt. Ungroundable figures return null.
A five-agent pipeline with retries runs for minutes — far beyond Vercel's request limits — and a crash at agent 4 must not re-bill agents 1–3.
The whole pipeline is one Inngest function with each agent isolated in its own
step.run(). Steps are checkpointed: a failed step retries up to 3× without re-running
earlier, expensive agents. The API route just fires an event and returns — async by construction.
Multi-agent pipelines drift: a deck slide can quietly contradict the feasibility estimate it was supposedly built from.
The pitch builder may only cite facts from an enumerated menu of upstream findings, with source URLs carried through unchanged. Adversarial critique agents audit at three points (paper, feasibility, pitch), each allowed exactly one regeneration to prevent loops.
Web search goes down, models return 503s mid-pipeline. Failing the whole run for a missing market section wastes everything already computed.
Each stage declares its failure mode: core agents retry then fail the project with a notification; market and feasibility skip, don't fail; the deck gracefully omits the market slide when the data is absent. The Gemini client falls back to a same-provider backup model on retryable errors.
Free-form JSON from a model breaks parsers, and provider-side schema support doesn't cover constraints like ranges, unions, or regex patterns.
One Zod schema per agent is both converted into a Gemini responseSchema (constraining
generation) and run as safeParse before persistence (source of truth). Constraints Gemini
can't express are still enforced by Zod — e.g. rejecting capital ranges where max ≤ min.
Verified against the public repository — no résumé padding.
| Layer | Technology |
|---|---|
| Framework | Next.js 14 (App Router) · TypeScript · React 18 |
| Database | Neon Postgres via Prisma 7 — one model per agent output, multi-tenant by institution |
| Background jobs | Inngest — durable execution, step-level checkpointing and retries |
| LLM | Google Gemini — direct REST, per-agent model + thinking-level config, automatic fallback model |
| Web search | Tavily, behind a swappable search-client interface |
| Validation | Zod — every agent output schema-validated before persistence |
| Auth | Clerk — middleware-gated workspace and onboarding |
| Storage | Cloudflare R2 (S3 SDK) — PDFs in, deck exports out |
| Real-time | Pusher (optional at runtime) + status polling fallback |
| Rate limiting | Upstash Redis — 5 analyses per user per hour |
| Deck export | puppeteer-core + @sparticuz/chromium (PDF) · pptxgenjs (PPTX) · docx (DOCX) |
| Testing | Vitest — including fault-injection via a swappable LLM transport |
I'm happy to walk through any of these decisions — the trade-offs, what broke, and what I'd do differently at 10× scale.